Multi-Robot Source Seeking in Dynamical Flowfield: A Game Theoretic Approach
Hassan Iqbal , Kristen Michaelson , Abayomi Adekanmbi
Abstract
This paper presents a distributed hybrid controller for solving online source seeking problem in a dynamical environment. By formulating the problem as a multiple pursuer multiple evaders game, we simultaneously addresses the problem of discrete assignment of mobile robots to sources as well as the continuous controls strategies for capturing individual sources of external dynamic flow-field.
Introduction
Source-seeking, sometimes referred as extremum-seeking, involves locating and tracking one or multiple spots, associated with the maximum or minimum value of interest, in a possibly dynamical environment.
It has been applied in surveillance, environment monitoring, disaster response etc.
For example, consider the scenario where a contamination is introduced in a water body or air through submarines or air-borne drones respectively.
Localizing and tracking all sources of contamination as soon as possible can play a crucial role in disseminating early warning as well as in coming up with localized corrective strategies.
In this paper, we are assuming that the external flow-field is dynamically changing. Under such circumstances, the mobile robots need to collaboratively assign tasks to each other and localize all the moving sources.
We formulate the problem of dynamical source seeking as a multiple pursuer multiple evader (MPME) game where identical pursuers represent mobile robots and evaders represent the sources moving passively in a dynamical flow field \( V_f(z,t)\).
For this work, we assume all the pursuers know positions of evaders. We further assume that pursuers can talk only to their neighbors.
We also assume all players know the external dynamic flow field. The kinodynamic constraints of pursuer \( i \) denoted by \(x_i(t)\) are given as:
\begin{equation}
\dot{x}_i = u_i(t) + {V_f}(z,t)
\tag{1}
\end{equation}
where \( u_i(t) \) is the control vector. We say that pursuer \(i\) can capture evader \(k\), denoted by \(y_k(t)\) when
\begin{equation}
x_i(t) \in \beta_r(y_k(t)) = {||x-y_k(t)||_2 < r}
\tag{2}
\end{equation}
where \( \beta_r(y_k(t))\) is open ball of radius r centered at evader \(k\). Then our problem formulates to as follows:
Given \(n\) identical pursuers and evaders and no prior assignment information, derive distributed control laws for every pursuer
\(i\) such that for any initial configuration \(x_i(t_0)\), there exists a \(T>0\) such that \(x_i(t)\) in \(beta_r(y_k(t))\) for all time \(t>t_0+T\), all pursuers \(i\) and evaders \(k\).
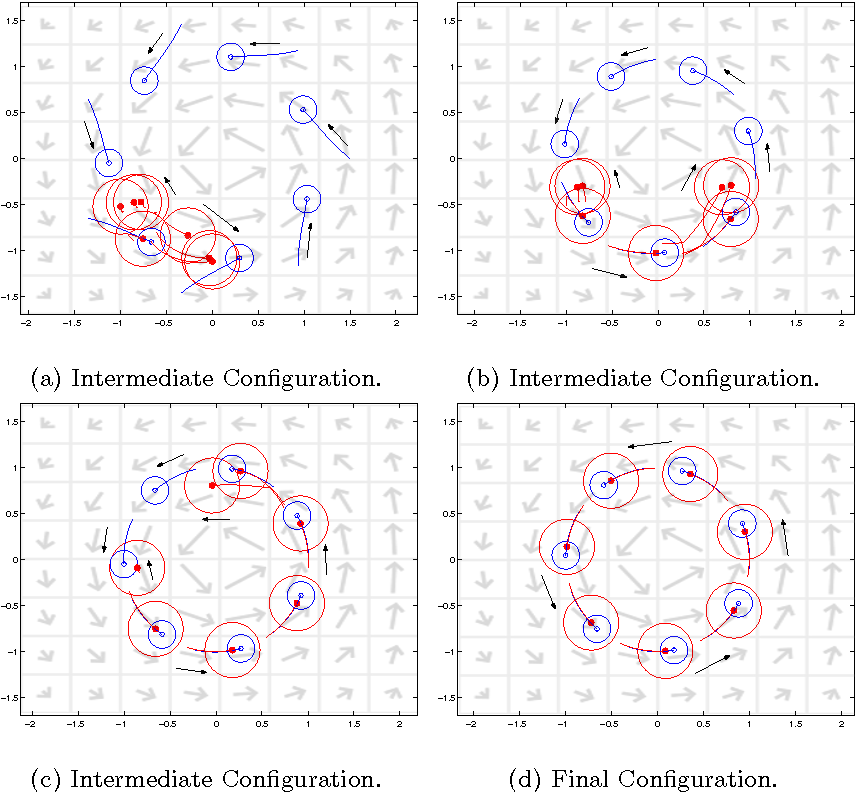
Specific Aim
We first aim to replicate the results presented in the paper, Distributed Hybrid Control for Multiple-Pursuer Multiple-Evader Games. We will begin with equal numbers of pursuers and evaders (although the paper also extends to a formulation with more evaders than pursuers). In this work, both the pursuers' and evaders' dynamics are simple motion. The pursuers' control inputs \(u_i\) are velocity vectors. The evaders do not strategize; instead, they follow pre-defined trajectories. The above figure shows the time-evolution of a game with 7 players. The pursuers start off gathered in one area. Meanwhile, the evaders begin to move in a circle. Eventually, the pursuers capture all the evaders. At every time step, each pursuer \(x_i\) "claims" the evader \(y_k\) closest to it. Define \(\gamma(x_i, y_k)\) = \( ||x_i - y_k||_2 \) and \(r(t) = Re^{-a(t - t_0)}\). The pursuer plans a trajectory based on the following strategy \begin{equation} \dot{x}_i = u_{R,a}(x_i, y_k, t) := -K\nabla\varphi_{R,a}(x_i, y_k, t) \tag{3} \label{eq:3} \end{equation} where \(\varphi_{R,a}(x_i, y_k, t)\) is a potential function defined as \(\varphi_{R,a}(x_i, y_k, t)\) = \(\frac{1}{r^2(t) - \gamma^2(x_i, y_k)}\). We aim to replicate their online task assignment policy; making sure all evaders are pursued. Next, we aim to extend Zavlanos et. al work to a game scenario in a dynamic flow field. The flow field will be known to the pursuers, and a new mapping from states to strategies eq. \ref{eq:3} will be developed based on this new information structure. The above figure was adapted from the Zavlanos et. al work to demonstrate how this might look. Additional possible extensions include:
- Pursuers must estimate the flow field.
- Pursuers must estimation positions of evaders at each time steps.
- Smarter evaders with knowledge of pursuers strategies maximizing their cost and making capture difficult for the pursuers.}
Navigation Approach 1
The pursuer strategy is defined in equation \ref{eq:3}. Evaluating the gradient term, we have \begin{equation} v_x = - 2K \frac{1}{\beta^2}(p_x - e_x) \tag{4} \end{equation} \begin{equation} v_y = - 2K \frac{1}{\beta^2}(p_y - e_y) \tag{5} \end{equation}
Navigation Approach 2
The second approach of pursuer navigation we tested was based on forward reachability set. We can show that the viscosity solution to the Hamilton-Jacobi equation governs the reachable set \(R(ys,t)\), where \(R(ys,t) = {x : φ(x, t) ≤ 0}\). \begin{equation} \frac{\delta \phi_0}{\delta t} + F |\nabla \phi_0| + V(x,t).\nabla \phi_0 = 0 \tag{6} \end{equation} with the initial condition \begin{equation} \phi_0(x,0) = |x-y_s| \tag{7} \end{equation} The level set equation governing the evolution of a front moving in a direction normal to itself at a constant speed F (> 0) and in a stationary environment. This implies that the vehicle’s optimal relative speed equals F, and its optimal heading is normal to the level sets of φ. Once the reachability front reaches the evader's location, we can find the optimal velocity control for the pursuer to capture evader in the minimum time, using the following solution: \begin{equation} \frac{dX^*_p}{dt} = F \frac{\nabla \phi_0(dX^*_p,t)}{|\nabla \phi_0(dX^*_p,t)|} + V(X^*_t,t) \tag{8} \end{equation}
Task Assignment Approach 1
We employed a hybrid system model with a number of discrete states functioning as a finite automaton; Each discrete state itself is comprised of a continuous dynamic process that could be modelled by differential or difference equation, and account for control inputs and disturbances. The hybrid task assignment and coupled navigation automaton approach allows our solution to be scalable; we can create a high-dimension representation for a nmulti-agent system and consider all states of the system. Our navigation and task assignment strategies follow these automatons, taken from Zalvanos et. al:
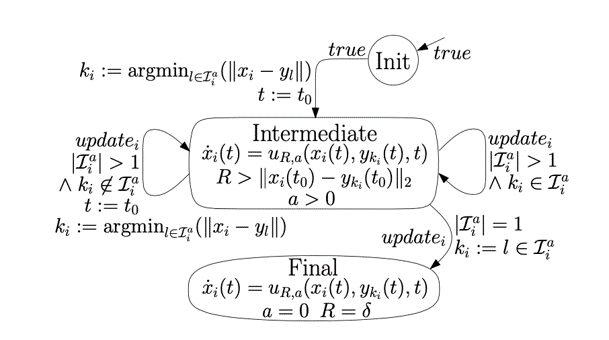
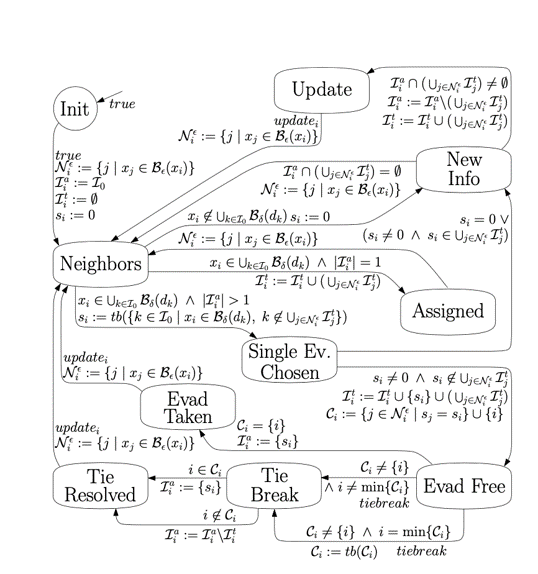
Task Assignment Approach 2
For finding the initial assignment that minimizes the pair wise distance between evaders and pursuers. we used a version of the Hungarian algorithm. To that end we solved a linear assignment problem by constructing a cost matrix based on the distance between pursers and evader. We simulated result with both the dynamic flow field and without.
Task Assignment Approach 3
Similar to the procedure in the hungarian method, we implemented a cost matrix based on the time to capture to minimize it.
Results
Each of the three task assignment strategies was executed 10 times without a flow field and 10 times in a circular flow field. At the beginning of each trial, the pursuers are placed in random locations in a 1x1 m box at the bottom left of the screen. The evaders always start in the same position. When the flow field is off, the evaders move in a circle. When the flow field is on, the evaders are placed in the flow field. The pursuers must "fight" against the flow field to capture the evaders. This increases time to capture. Pursuer-evader assignments are computed at each time step. Pursuers may maintain the same target, or be assigned a new one. In the case of Zavlanos task assignment, they may remain unassigned for a few time steps at the beginning of the game.
The table below summarizes the performance of each task assignment algorithm. The time given is the average of all the successful trials. A trial was considered to have failed if capture was not achieved by 30 s.
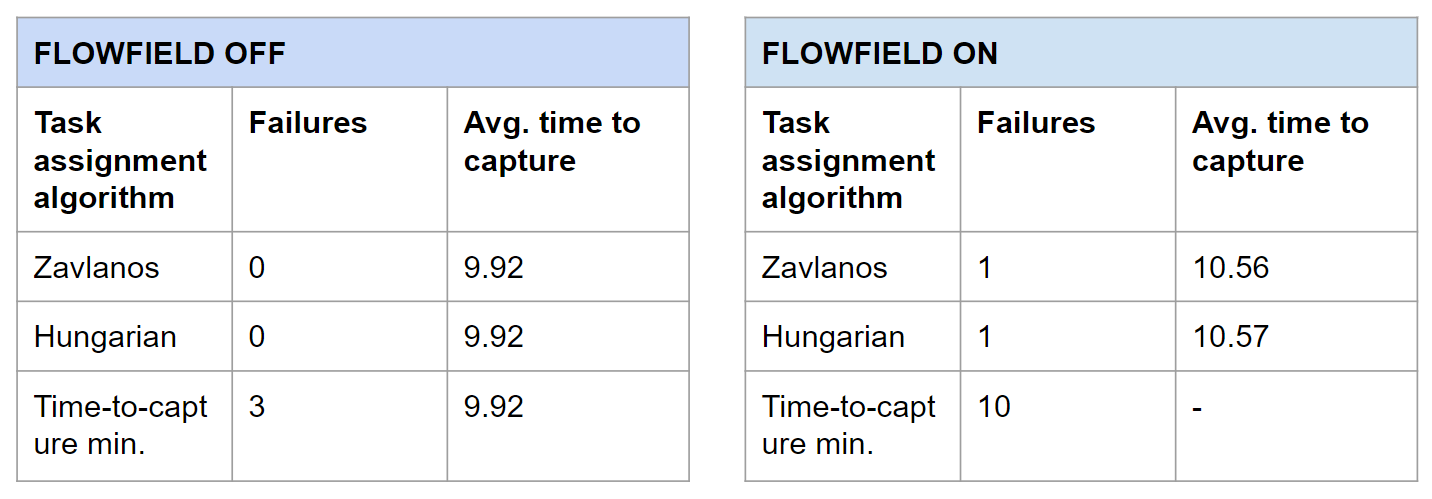
It is important to note that reported time is time steps (dt = 0.01), not CPU time. Some task assignment algorithms likely take longer to run than others. That said, the strategies were remarkably consistent (mean = median = mode), even with random pursuer starting positions.
References
Code implementation can be found here
Multi-agent on-line extremum seeking using bandit algorithm, Du, Qian, Claudel and Sun, 2021.
Distributed hybrid control for multiple-pursuer multiple-evader games,Zavlanos and Pappas, 2007.
Future Work
- Pursuers to collaboratively estimate the (adversarial) flow field and localize all evaders at each time step via concentration measurements.
- Smarter evaders with knowledge of pursuers strategies maximising their cost making capture difficult for the pursuers.
- Obstacles; simple integration with our forward reachable set approach.
- Test on hardware.